Avancer lentement et ne rien casser
Dans mon dernier billet, je racontais ma tentative d’exploiter le code source de l’impôt sur le revenu publié par la DGFiP. J’écrivais alors la chose suivante:
Au moment où ce billet est publié, le code généré par Mlang est cependant toujours faux. En effet, un effet secondaire de ce travail de formalisation et de validation a été de découvrir que le code M publié par la DGFiP ne contient pas toutes les informations nécessaires à répliquer le calcul de l’impôt. Techniquement, le code M est appelé plusieurs fois avec des valeurs particulières pour certaines variables. Cette subtilité technique n’avait pas été détectée au moment du hackathon et de la première publication du code. J’ai pu en informer la DGFiP, qui met actuellement des moyens en œuvre pour me permettre de récupérer dans leur système les informations concernant ces appels multiples du code M avec différents paramètres. Une fois ces informations récupérées, je pourrai achever le travail de formalisation et valider Mlang sur les jeux de tests officiels de la DGFiP.
Un an plus tard, la promesse est tenue! Mlang, le nouveau compilateur pour le langage de programmation maison « M » de la DGFiP, est opérationnel et permet de répliquer le calcul de l’impôt chez soi comme c’est fait à Bercy. Cela permet de vérifier votre dernier avis d’imposition, mais également de regarder plus précisément comment l’impôt sur le revenu est calculé ! Par exemple, cette ligne applique le barème progressif de l’impôt après application du quotient familial. Certes, tout n’est pas limpide et il faudrait quasiment tout réécrire pour rendre ça compréhensible; mais c’est une autre histoire…
Encore mieux, la DGFiP elle-même fait un pas vers plus de transparence et de modernité, car Mlang deviendra à terme le compilateur officiel utilisé en production par le service qui calcule l’impôt sur le revenu ! Move fast and break things est le crédo des informaticiens « disruptifs » du monde des startup; ici, il s’agit plutôt d’appliquer le crédo inverse, Move slow and fix things, car on ne peut pas se permettre de casser l’impôt sur le revenu. Pour y arriver, il faut néanmoins casser les méthodes traditionnelles de gestion de projet.
Dans ce billet, je vous propose de plonger au cœur du réacteur du calcul de l’impôt, et de comprendre comment notre domaine de recherche, les méthodes formelles, a permis à Raphaël Monat et moi de créer une alternative moderne et opérationnelle à un composant critique des systèmes informatiques de la DGFiP. Le but est qu’après avoir lu ce billet, vous soyez capable de lire et comprendre notre article de recherche sur le sujet (co-écrit avec mon directeur de thèse Jonathan Protzenko) et que vous soyez incollables sur les avantages et inconvénients des langages dédiés.
Enfin, je m’aventure également sur une terrain plus organisationnel : à une vision industrielle de l’informatique de gestion reposant sur l’emploi en masse de programmeurs peu qualifiés, je fais le plaidoyer sur les projets critiques d’un emploi d’artisans qualifié du logiciel. En bref: n’hésitez pas à recruter plus de spécialistes des langages de programmation pour maintenir vos logiciels critiques !
Une architecture inhabituelle
L’héritage de 30 ans d’exploitation
La Direction Générale de Finances Publiques (DGFiP) a, parmi ses missions, celle de lever l’impôt sur le revenu (IR). Le montant de l’impôt dépend des revenus du foyer fiscal, selon un barème progressif. Chaque année, les ménages français envoient à la DGFiP une déclaration de revenus, en grande majorité sous la forme d’un formulaire à remplir sur impots.gouv.fr. Ce formulaire, auquel vous avez sûrement déjà été confronté, comporte de multiples cases permettant de différencier les sources de revenu : plusieurs centaines de cases en fait. Et oui, le droit fiscal comporte énormément d’exceptions dont il faut tenir compte lors du calcul de l’IR. On pourrait débattre de la pertinence d’une simplification, mais ce n’est pas l’objet de ce billet.
Donc une fois la déclaration reçue, la DGFiP dispose de tout ce dont elle a besoin pour calculer l’impôt sur le revenu. Que se passe-t-il alors ? Toutes les valeurs renseignées dans les cases de la déclaration se transforment en entrée pour un programme informatique très spécial, qui calcule le montant de l’impôt selon les règles législatives du Code Général des Impôts.
Qui dit programme dit langage de programmation. Et c’est là que la DGFiP fait quelque chose d’inhabituel, puisqu’au lieu de coder le programme en C, en Java ou en Python, elle a choisi le langage M. Qu’est-ce que le langage M ? C’est un langage « dédié » (domain-specific language ou DSL) créé par la DGFiP pour la DGFiP en 1990.
En effet, voici un extrait du code source publié:
regle 521010:
application : bareme , iliad ;
pour x=0,5;y=1,2;z=1,2:
DSxyz = somme(i=1..9: max(QFxyz - LIMINFBARi, 0) * (TAUXi / 100)) ;
Même sans connaître le langage M, on peut deviner des boucles, un opérateur
de somme appliqué à un maximum multiplié par un taux. Et en effet, ce bout de
code est celui qui calcule le montant de d’impôt à payer (« droits simples », DS)
en fonction du quotient familial (QF) et des taux des différentes tranches
de l’impôt sur le revenu.
Même s’il paraît austère au premier abord, le langage M a été conçu pour les spécialistes du droit fiscal et ses règles de calcul : il permet d’exprimer de manière concise les formules fiscales. Lors de sa création en 1990, l’objectif était que les juristes spécialistes du droit fiscal à Bercy puissent directement lire et écrire le code M, sans passer par les informaticiens.
Le code M existe donc depuis 30 ans, et est mis à jour chaque année après le vote du Projet de Loi de Finances qui modifie le barème et les modalités de l’IR. Cependant, le louable objectif de se passer des informaticiens a dû être abandonné en cours de route, puisque c’est bien une équipe d’informaticiens du bureau SI-1E de la DGFiP qui se charge de la maintenance et de l’évolution du code.
Revenons à ce qui se passe lors du calcul de l’impôt. Parmi les variables du
code M, certaines contiennent directement les valeurs de cases de la déclaration
d’impôt. D’autres sont des variables intermédiaires, et enfin une poignée
correspondent au montant d’impôt à payer, comme IRNET. Il suffit donc de
calculer les valeurs des variables les unes après les autres pour arriver
au résultat final. Simple non ?
Pas si simple, car pour exécuter un programme écrit en M, il faut d’abord le traduire vers un autre langage que la machine comprend. En 1990, lorsque M a été créé, la DGFiP a choisi le langage C comme cible, et traduit donc le code M en code C grâce à un compilateur que nous appellerons « compIRateur » avant de l’exécuter. À l’époque, C était un langage « haut-niveau » et à l’écosystème déjà mature, donc ce choix était tout à fait raisonnable.
Pour compléter le tableau, il nous faut rajouter à la base de code M publiée un ensemble de fichiers non-publiés, répondant au mystérieux nom de « INTER ». C’est à cause de la non-publication de ces fichiers INTER que je n’avais pas toutes les informations nécessaires à la réplication du calcul dans mon billet précédent.
Ces fichiers INTER sont écrits en C et interagissent directement avec la traduction en C des fichiers M. Ils contiennent la logique d’un mécanisme de droit fiscal appelé « liquidations multiples ». Il s’agit de recalculer l’impôt plusieurs fois de suite avec des entrées différentes pour par exemple plafonner le montant des avantages fiscaux, ou le bénéfice lié au quotient familial.
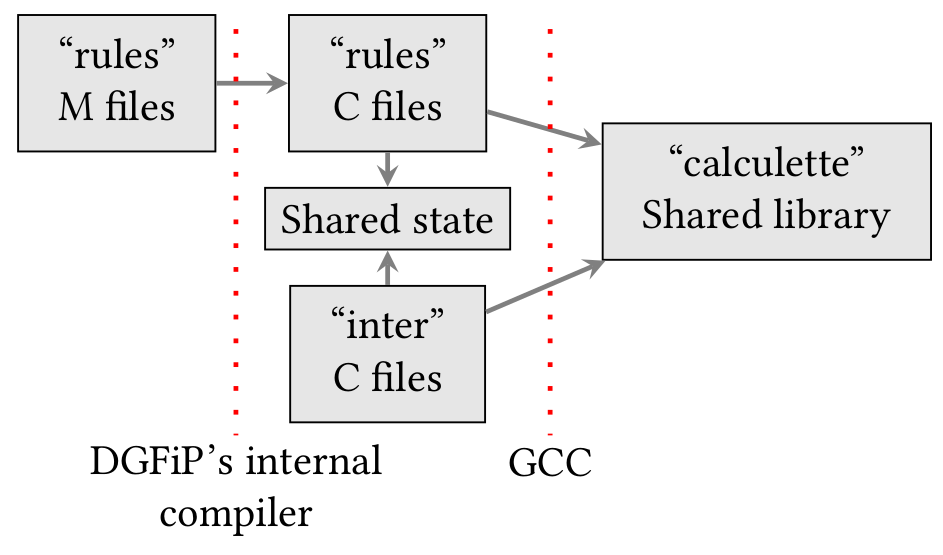
Langage M, fichiers M, fichiers INTER écrits en C ; toute cette architecture est bien compliquée. N’aurait-il pas été plus facile de tout écrire en C dès le départ ?
Pourquoi utiliser un langage dédié ?
Cette question est pertinente ; arrêtons nous un instant pour instruire à charge et à décharge le procès du choix du langage M en 1990. Un élément clé du contexte du choix est la nature du problème à résoudre : le calcul de l’impôt. Un programme qui calcule l’impôt n’est pas n’importe quel programme informatique, et l’on peut faire des hypothèses fortes sur ce dont on a besoin pour l’écrire.
Première hypothèse : le calcul de l’impôt termine toujours. On n’a donc a priori pas besoin de récursion générale ou de boucles infinies pour écrire le programme. Deuxième hypothèse: les règles de calcul de l’impôt sont assez simples pour être exprimables uniquement à base d’arithmétique. La deuxième hypothèse est plus discutable que la première, car l’imagination du législateur fiscal est sans limite, mais posons la comme vraie comme l’a sûrement fait la DGFiP en 1990.
Sous ces hypothèses, la solution d’un langage dédié (DSL) est séduisante : elle permet de limiter ce qu’un développeur peut écrire, en l’occurrence uniquement des règles de calcul arithmétiques sur des variables : pas de pointeurs, pas de fonctions, pas de structures de données. Et cette limitation est cruciale pour respecter une contrainte majeure de la DGFiP : la performance. En effet, l’enveloppe en temps de calcul pour calculer l’impôt d’un foyer fiscal est de quelques millisecondes. Cette contrainte est nécessaire car avec 37 millions de foyers fiscaux, il faut que chaque calcul aille très vite pour ne pas exploser le temps total.
En n’utilisant que des expressions arithmétiques, sans même de conditionnelles, le code utilisé par la DGFiP est exceptionnellement rapide : les 600 000 lignes de code C généré par le compIRateur s’exécutent en une milliseconde seulement. Cette performance remarquable est liée à la forme du code C généré qui utilise plusieurs astuces ingénieuses, comme celle de regrouper les variables du M dans un grand tableau qui tient dans le cache du processeur pour optimiser les accès mémoires.
Autre avantage du DSL : le développeur M n’a pas besoin de spécifier dans
quel ordre les variables sont calculées. En effet, le compIRateur réordonne
automatiquement les variables en suivant l’ordre induit par le graphe de dépendance
du code. Et avec plus de 27 000 variables dans le code, cette fonctionnalité
est extrêmement pratique, car les textes législatifs que le code est censé
suivre ne définit pas les variables dans l’ordre dans lesquelles elles sont
calculées. Concrètement, imaginez que vous avez X = 0,
Y = X + Z et Z = 2 * X. En analysant les dépendances entre les variables,
on déduit qu’il faut calculer X en premier, puis Z et enfin Y.
Ce dernier point sur le calcul des dépendances éclaire aussi pourquoi la DGFiP a choisi un langage dédié externe, avec sa propre syntaxe et compilateur, plutôt qu’un langage dédié embarqué à l’intérieur de C, à base de macros du pré-processeur qui émulent la syntaxe du M. Aussi puissantes que soient les macros du pré-processeur C, elles ne permettent pas de calculer l’ordre topologique d’un graphe de dépendance. Pour cela, un véritable compilateur est requis.
Cepdendant, le choix du DSL vient aussi avec son lot d’inconvénients. Premièrement, un langage dédié commence forcément sur un marché de niche, n’est pas enseigné à l’université et il est donc nécessaire d’y former en interne ses développeurs. Heureusement, le langage M n’est en soi pas très compliqué, donc y former des développeurs n’est pas l’obstacle majeur. Deuxièmement, le manque d’outillage. En effet, un langage de programmation vient avec un outillage d’aide au développement essentiel : surlignage syntaxique, analyses statiques connectées à des environnements de développement intégré, etc. Le langage M ne possède pas un tel outillage, à cause du faible nombre de personnes qui l’utilisent. Mais en 1990, la notion même d’outillage de langages de programmation au delà du compilateur était balbutiante ; ce désavantage devait sembler mineur à l’époque.
Troisièmement et de manière plus importante, ce qui fait la force d’un DSL est aussi sa faiblesse : en restreignant le langage à des assignations de variables par des expressions arithmétiques, le langage M prive le programmeur de tout outil permettant l’abstraction. Notamment, l’absence de fonctions définies par l’utilisateur mène à la nécessité de dupliquer le code. La duplication de code est l’ennemi mortel du programmeur, car elle rend plus difficile la maintenance d’une base de code où toute modification doit être répliquée à plusieurs endroits, avec tous les risques d’oubli et d’erreur que cela comporte.
C’est d’ailleurs entre autres le manque de fonctions dans le langage M qui a conduit a la création des fichiers C INTER qui eux comportent des fonctions : en effet, la logique fiscale des liquidations multiples conduit à considérer la liquidation de l’impôt comme une fonction à appeler avec différents paramètres, ce qu’il est impossible d’exprimer sans duplication de code en M.
Moderniser sans rien casser
C’est donc cette architecture historique que Raphaël et moi avons découvert lorsque nous avons pu avoir accès au code source complet non-publié de la DGFiP. Dès lors, l’objectif initial de Mlang qui était de rendre utilisable le code M publié par la DGFiP est devenu beaucoup plus complexe. En effet, pour que ce code M publié soit utilisable, il fallait aussi que Mlang fasse le boulot des fichiers INTER qui eux ne seront jamais publiés pour raisons de sécurité.
À ce stade, nous avons longuement discuté avec les programmeurs de la DGFiP. C’est d’ailleurs de ces discussions que nous avons pu comprendre l’historique de la situation, ainsi que les diverses contraintes qui s’imposaient au projet. Il est rapidement apparu que l’objectif initial de Mlang recoupait un objectif interne de la DGFiP, qui est de garder la maîtrise sur la compilation du langage M. En effet, Après 30 ans d’exploitation, les développeurs originels du compIRateur interne de la DGFiP partent à la retraite, posant un problème de perte de compétence. Et le code source du compIRateur auquel nous avons pu avoir accès, écrit en C et en 1990 pour la plus grosse partie, accuse une certaine obsolescence par rapport aux bonnes pratiques d’écriture de compilateur mises en place depuis 1990 dans la communauté. La création de Mlang était donc une très bonne opportunité pour la DGFiP de moderniser une brique logicielle essentielle à l’architecture du calcul de l’IR.
Une approche incrémentale
Un des impératifs de toute tentative de modernisation de la calculette IR est l’incrémentalité. En effet, la calculette IR est au centre du système informatique de la DGFiP, et une myriade d’applications embarquent le module de calcul de l’impôt : simulateur en ligne, logiciel métier pour les conseillers des centres locaux des finances publiques, etc. Il est donc nécessaire pour la solution modernisée de garder la même interface vis-à-vis de ses applications clientes, concrètement une interface C.
De manière tout aussi importante, une modernisation doit prendre en compte la gestion des compétences informatico-fiscales nécessaires à la transformation des textes législatifs régissant le calcul de l’IR en code informatique. Actuellement, la DGFiP possède une compétence forte et une base de code éprouvée avec le langage M. Passer du M à un autre langage de programmation traditionnel signifierait la réécriture des règles fiscales dans un langage pas forcément adapté à la forme des règles fiscales. Dans un autre contexte similaire, les règles de paie des soldats de l’armée de Terre, une initiative de modernisation appelée Louvois a montré les dangers de minimiser la complexité de ces règles en considérant une telle réécriture comme un projet informatique normal.
Malgré ces contraintes, une modernisation incrémentale peut apporter de nouvelles fonctionnalités au système de calcul de l’IR, par exemple:
- une mesure fine de la couverture des tests, notamment au niveau des valeurs individuelles des variables M;
- de nouvelles cibles pour la compilation du langage M, pour faciliter l’interopérabilité avec d’autres applications informatiques de l’État;
- une analyse de la précision des calculs utilisant des flottants.
Une nouvelle architecture centrée sur le compilateur
La solution de modernisation que nous proposons avec Raphaël repose sur Mlang et plus généralement sur la compilation entre différents langages, comme autant de traits d’union entre les différents composants de cette architecture complexe.
Premièrement, Mlang est un compilateur complet pour le langage M, basé sur une sémantique formelle obtenue par rétro-ingénierie. Cette sémantique est présentée dans notre article de recherche et guide l’implémentation de Mlang. Par exemple, contrairement au compIRateur originel de la DGFiP, Mlang possède un interpréteur de M qui sert de référence au langage : le débogage se fait d’abord en utilisant l’interpréteur qui dispose de fonctionnalités adaptées (afficher les valeurs des variables, etc.). Une fois que le bug est réglé dans l’interpréteur, alors le comportement devrait être correct dans chacun des langages cibles de Mlang (C, Python, etc.). Cela permet de séparer les problèmes, en permettant à l’utilisateur de savoir si son bug vient du code M ou du compilateur.
Deuxièmement, nous avons amélioré Mlang pour gérer et répliquer les fonctionnalités implémentées dans les fichiers INTER non-publiés par la DGFiP. Pour cela, nous avons longuement étudié le code des fichiers INTER afin de déterminer exactement ce qu’ils faisaient. Dans les fichiers INTER, une structure de données essentielle est mise à jour tout au long du code effectuant les liquidations multiples : le tableau général des variables, ou TGV. Le TGV est un tableau C qui contient les valeurs de toutes les variables déclarées dans le code M. Au fur et à mesure que le C traduit du M est exécuté, le TGV est mis à jour. Lorsque le code INTER appelle le code M, il passe en entrée le TGV « vide » qui ne contient que les variables d’entrée de M (correspondant aux cases de la déclaration de revenu), et reçoit en retour le TGV « rempli » avec les valeurs calculées.
Quand on regarde le code des fichiers INTER, on s’aperçoit que leur rôle est d’appeler à plusieurs reprises le code M, tout en gérant l’état du TGV entre les appels en sauvegardant la valeur de certaines variables ou en modifiant la valeur de variables M spéciales qui ressemblent à des drapeaux activant ou désactivant certaines parties du code M. Or, parce que le langage C est très bas-niveau, nous nous sommes aperçus que la logique pure contenue dans les fichiers INTER était relativement simple, mais cachée parmi des masses de code standard en C pour gérer les pointeurs et l’état mutable.
Nous avons donc décidé avec Raphaël de créer un deuxième langage dédié externe compagnon pour exprimer la logique contenue dans les fichiers INTER. Ce langage, que nous avons appelé M++, ressemble à ça:
compute_benefits():
if exists_deposit_defined_variables() or exists_taxbenefit_ceiled_variables():
partition with var_is_taxbenefit:
V_INDTEO = 1
V_CALCUL_NAPS = 1
NAPSANSPENA, IAD11, INE, IRE, PREM8_11 <- call_m()
V_CALCUL_NAPS = 0
iad11 = cast(IAD11)
ire = cast(IRE)
ine = cast(INE)
prem = cast(PREM8_11)
PREM8_11 = prem
V_IAD11TEO = iad11
V_IRETEO = ire
V_INETEO = ineLa syntaxe ressemble à Python car M++ ressemble à un langage de script. M++
possède des fonctions, conditionnelles, des assignations de variable et
une fonction spéciale : call_m. Les variables en lettres capitales sont
des variables du TGV de M, les autres sont des variables locales de M++.
En utilisant le langage dédié haut-niveau M++, Raphaël et moi sommes capables
d’exprimer plus de 5 500 lignes de code C INTER (commentaires compris)
en une centaines de lignes de M++. Nous pensons donc que la maintenance du code
M++ sera considérablement plus simple que le code M. De plus, M++ est intimement
lié à M au travers de Mlang. En effet, à l’intérieur de Mlang, les appels
à call_m sont simplement inlinés dans une même représentation
intermédiaire. Voici d’ailleurs l’architecture de Mlang, structurée par
de nombreuses représentations intermédiaires :

M et M++ sont fusionnés dans la représentation BIR, ce qui permet de considérer en un seul programme l’ensemble des fichiers sources contenant la logique de calcul de l’impôt, qu’ils soient écrits en M ou en M++.
Le langage M++ ne cherche pas à être élégant dans son design, et il ne suit pas un paradigme traditionnel de programmation en particulier. Au contraire, c’est un outil complètement ad-hoc qui s’adapte à la situation particulière des fichiers INTER. En créant un langage dédié à partir d’un code existant, la démarche est d’extraire la substantifique moelle logique de la base de code afin de laisser de côté tout ce qui n’est pas essentiel. Le passage du C des fichiers INTER à M++ limite de fait ce qu’on peut exprimer, comme à chaque fois que l’on passe d’un langage généraliste à un langage dédié. Mais l’analyse de l’historique des fichiers INTER, qui reflète l’évolution du droit fiscal français, laisse à penser qu’il n’y aura pas besoin de nouvelle fonctionnalité du langage tant que nous restons sur le même paradigme de calcul de l’impôt.
Il est cependant tout à fait possible que le législateur vote une loi qui introduit une complication du calcul telle que M et M++ seront à leur tour insuffisants pour exprimer le calcul informatiquement. Dans ce cas et grâce à la maîtrise formelle des deux langages, il sera toujours possible de rajouter une fonctionnalité adaptée au langage et ainsi assurer la pérennité de la maintenance du code.
Sans rien casser ?
Tout au long du processus d’élaboration de notre solution autour de Mlang, nous avons veillé à vérifier méticuleusement que nous n’étions pas en train de casser le calcul de l’IR.
Pour cela, la DGFiP nous a communiqué l’ensemble de ses jeux d’essai privés. Les jeux d’essai de la DGFiP consistent en un grand nombre de foyers fiscaux fictifs (entre 500 et 1000), normalement écrits par des juristes fiscalistes qui calculent à la main le montant d’impôt dû. Mlang est donc validé sur ces jeux d’essai, pour l’instant pour le calcul de l’impôt sur les revenus 2018 et 2019. Dans un second temps et quand Mlang sera considéré pour une mise en production, les résultats de Mlang pourront être comparés avec ceux de l’ancien système sur l’ensemble des foyers fiscaux français, garantissant une assurance maximale pour la transition.
Cependant, ceci concerne uniquement la validation en interne de Mlang. Raphaël et moi tenions à ce que l’évaluation de Mlang soit reproductible en dehors de la DGFiP. Or, la DGFiP n’a pas souhaité que ses jeux d’essai soient rendus publics. Nous avons donc du trouver une solution pour créer de nouveaux jeux d’essais, distincts de ceux de la DGFiP.
Il était hors de question que nous écrivions des cas de tests à la main, puisque nous n’y connaissons rien en droit fiscal. Nous avons donc pris le parti d’utiliser une autre technique classique d’ingénierie logicielle : le fuzzing ou test à données aléatoires. Le principe est le suivant : on génère aléatoirement des déclarations de revenu de foyers fiscaux jusqu’à ce qu’un des essais corresponde à un foyer fiscal réaliste, qui devient un jeux d’essai à part entière. Ces jeux d’essai sont ensuite validés en observant les résultats calculés avec l’ancien système de la DGFiP. Plusieurs questions se posent immédiatement ? Qu’est-ce qu’un foyer fiscal « réaliste » ? Combien de jeux d’essai faut-il générer pour couvrir « tout le code » ?
Nous avons considéré qu’un foyer fiscal était « réaliste » dès lors qu’il ne lève aucune des conditions d’erreur qui sont vérifiées dans le code M. Ces conditions, au nombre de 500, servent à valider la cohérence de la déclaration de revenu. Par exemple, lorsqu’une case A précise « part des revenus de la case B dédiée à … », alors le montant de la case A doit être inférieur au montant de la case B. Le but du fuzzing est donc de trouver des jeux d’essai qui satisfassent ces 500 conditions impliquant des centaines de variables d’entrée, ce qui est loin d’être simple!
Pour obtenir des résultats rapidement, nous utilisons une technique de fuzzing un peu astucieuse, basée sur l’outil AFL. Dans ce fuzzing guidé par la couverture de nouveaux chemins d’exécution dans le ficher binaire testé, la génération aléatoire est biaisée en faveur des cas de tests qui permettent d’accéder à un résultat différent de toutes les tentatives précédentes. Cette idée simple raffinée par de nombreuses heuristiques permet à l’exploration aléatoire d’aller rapidement dans tous les coins du programme.
En l’occurence, l’utilisation de AFL nous permet d’obtenir des milliers de foyers « réalistes » en seulement quelques heures de test en continu sur une machine assez puissante. Un autre utilitaire, afl-cmin permet ensuite d’enlever les doublons qui testent les mêmes chemins dans le binaire pour arriver à un corpus minimisé de jeux d’essai qui offre une couverture optimale du programme de départ. Ce corpus minimisé compte quelques centaines de jeux d’essai pour les versions 2018 et 2019 du calcul de l’impôt sur le revenu.
Même si ces jeux d’essai « réalistes » contiennent généralement des combinaisons de revenus complètement irréalistes pour un foyer fiscal, ils ont le bénéfice d’être assez diversifié pour exercer toutes les combinaisons différentes de situations pour le calcul de l’IR, ce qui est difficile à obtenir lorsque l’on écrit soi-même les jeux d’essai à la main. Aussi peut-être serait-il préférable que les juristes qui écrivent les jeux d’essai partent directement des foyers fiscaux trouvés par fuzzing plutôt que d’en inventer, afin d’avoir une validation optimale de l’implémentation du calcul de l’IR.
Des langages dédiés pour le logiciel critique
Durant ce long voyage sous le capot du moteur de calcul de l’IR de la DGFiP, nous avons rencontré tout un bestiaire de langages exotiques et de techniques issues de méthodes formelles. J’aimerais terminer ce billet en prenant un peu de recul et en dégageant quelques raisons fondamentales pourquoi les langages dédiés et les méthodes formelles sont un outil très puissant pour assurer la qualité optimal d’un logiciel critique sur le long terme.
La difficulté de la maintenance à long terme
Aucun logiciel n’est éternel. Mais certains, de par les missions qu’ils accomplissent, ont pour vocation à être utilisés jusqu’à une durée indéterminée. Dans les années 60 et 70, les institutions bancaires du monde entier ont informatisé leur système de gestion des transactions en utilisant le langage de programmation COBOL. 60 ans plus tard, COBOL n’est plus enseigné à l’université et est largement considéré comme obsolète, mais les banques l’utilisent toujours pour faire tourner l’économie mondiale. Le choix d’un langage de programmation est nécessaire pour débuter un projet, mais même en choisissant un langage populaire aujourd’hui, on est pas à l’abri du zeitgeist informatique qui frappe d’obsolescence nombre de langages, frameworks et technologies.
Considéré sur des échelles de temps de la durée de plusieurs carrières, il est peu probable qu’une technologie d’aujourd’hui soit toujours enseignée à l’université dans 70 ou 80 ans. Et à mesure que les programmeurs originels partent à la retraite, il devient impossible de compter sur le marché du travail pour fournir une main d’œuvre qualifiée et prête à l’emploi.
Quelles stratégies adopter pour se prémunir contre l’obsolescence dans de tels projet de très long terme ? Une première solution est accessible aux très grosses organisations : la création d’un langage généraliste maison. C’est le cas du langage Ada, créé dans les années 1980 par le département de la défense américain (DoD). En imposant le langage dans tous ses projets, le DoD a pu créer de toutes pièces une demande de programmeurs Ada suffisante pour que la communauté Ada atteigne la masse critique qui lui permette de survivre sur le long terme. Avec suffisamment d’utilisateurs et de financement à long terme, Ada a pu recevoir de nombreuses mises à jour et son outillage s’adapte aux tendances modernes des langages de programmation.
L’agilité par le langage dédié
Cependant, toutes les organisations n’ont pas la même taille ou le niveau de planification et de financement que le département de la défense américain. Dès lors, une deuxième stratégie s’avère intéressante pour les projets de taille plus modeste mais qui ont aussi cette contrainte de maintenance à très long terme.
Ce que l’exemple de la DGFiP nous apprend, c’est que grâce à l’utilisation d’un langage dédié, il suffit de deux doctorants à temps partiel pour moderniser un compilateur ; à comparer avec la force de frappe nécessaire pour porter une base de code. Certes, il est toujours plus facile pour un chef de projet informatique de recruter en masse des développeurs peu qualifiés plutôt que de trouver et de fidéliser des profils à compétence spécifique comme ceux de Raphaël et moi.
Cependant, un langage dédié doté d’un compilateur bien maîtrisé par des spécialistes formés aux méthodes formelles est une formidable assurance sur l’avenir et l’interopérabilité du projet. Fondamentalement, un langage dédié agile qui s’adapte aux exigences fonctionnelle et au passage du temps démultiplie l’expressivité de la base de code. En réalité, code et langage forment un tout : seul l’exécution du code selon la sémantique du langage importe.
Avec un langage généraliste établi comme C et Java, on ne dispose que du levier du changement du code pour adapter et modifier son logiciel. Avec un langage dédié et un compilateur maîtrisé, le langage lui-même devient un outil au service de l’évolution du logiciel, et non plus un mal nécessaire à choisir au début et qui se transforme progressivement en dette technique insurmontable.
Revenons au cas du M : ce langage dédié a maintenant 30 ans, notre proposition de modernisation a-t-elle le potentiel de perdurer autant de temps ? Impossible de le savoir à l’avance, mais ce que l’on peut dire, c’est que les bases sur lesquelles partent M et M++ maintenant sont beaucoup plus solides que celles sur lesquelles M reposait depuis 1990. Doté d’une sémantique claire, d’un compilateur écrit dans un langage fonctionnel et structuré selon une architecture claire et extensible, le langage bénéficie de l’évolution de 30 ans de bonnes pratiques en théorie de la compilation et en méthode formelles.
Mais attention, le langage dédié peut se transformer en une arme à double tranchant sans la compétence appropriée ! On ne change pas la sémantique d’un langage sur un coup de tête, car un changement minuscule peut casser tout une base de code. C’est pour cette raison que les ingénieurs compilations et les spécialistes des méthodes formelles, loin d’être rendus obsolètes par les méthodes d’apprentissage statistiques, restent et seront pour très longtemps absolument cruciaux. L’étude des langages de programmation, de la théorie de la compilation et des méthodes formelles apporte une vraie compétence spécifique extrêmement utile pour de nombreux projets informatiques critiques.
Conclusion : faites confiance aux artisans du langage
De manière plus imagée, le choix du langage dédié et de sa compétence associée en méthode formelles peut être comparé au choix de l’artisanat par rapport à un processus industriel que serait le portage de code d’un langage à un autre. L’artisanat possède une longue tradition de transmission du savoir sur le long terme, basé sur un petit nombre de praticiens indépendants formés à des compétences de haut niveau avec une relative polyvalence. À l’opposé, l’industrie vise à transformer le processus de production en une chaîne assez rigide de tâches standardisées réalisée par des ouvriers peu qualifiés. Comme les autres secteurs de production, l’informatique a tendance à s’industrialiser au fil du temps.
Mais l’industrialisation suppose la masse critique et souvent la recherche infinie de la croissance. Et cette analogie s’applique également pour les langages informatiques. Donc avant de choisir à contre-cœur un langage établi et industriel pour votre projet informatique à long terme, demandez-vous si vous voulez vraiment vous inscrire dans une logique industrielle de croissance infinie, ou s’il n’est pas plus opportun d’en confier la réalisation à des artisans du langage, qui sauront vous produire et maintenir un beau petit logiciel du terroir !