Building a language that people want
It has been 5 years since I have submitted the Catala paper to the International Conference on Functional Programming. Since then, I have not published any significant contribution to the science of Programming Languages (PL), and actually stopped doing research in that area. Why? Well, I have simply decided at the end of my PhD that I wanted to turn Catala into a tool actually used by people in production. This blog post sums up what I have been up to more concretely, and illustrates the gap between research and practice, tech and product, in the context of designing and building domain-specific programming languages (DSL). It is not meant as a cautionary tale, I would rather hope it helps demystifying the road to adoption for PL people. The road is long and windy, but it is a rewarding journey. I personally made a lot of new friends, and I like to think it made me somewhat wiser.
The product stack of a DSL
We’re all standing on the shoulders of giants, and I did not start from scratch. My drive for getting PL research adopted in the real world was heavily inspired by the Everest project of verified cryptography, which managed to fix TLS and land verified cryptography into Firefox and Python. Formally verified cryptography has now entered an era of industry, with demand stemming from the new post-quantum cryptography primitive implementations being deployed these days.
For Catala, getting into the hands of users means being adopted by the IT departments of large government agencies. These agencies are responsible for producing and maintaining the complex software systems that handle tax and social benefits computations. As it is often the case with legally-specified government processes, these computations are very hard to get right. The teams of software engineers and domain experts inside the IT departments of government agencies have one requirement for their tooling: they want something that works. But what does that mean for a domain-specific programming language like Catala?
At its heart, Catala is just a lambda-calculus with a little bit of default logic sprinkled on. To make it a real domain-specific language (DSL), we gave it some syntax and semantics (altough apparently it could have been even simpler), and proved type soundness. For a PL researcher, the job is done: when the paper published, it is time to move on.
But the teams over at the IT departments of large government agencies do not feed on papers. They do not want a logic, they do not even want a programming language, they want a product that they will use daily, as a team, for interacting with the rest of their organization and the outside world. The software engineers care about Software Engineering features, not Formal Methods theories!
It is counter-productive to only advertise formal proofs and proper semantics to try and convince a software engineer to adopt your programming language. People will just shrug, you’re not connecting to their needs.
An excellent and very popular series of books to learn Formal Methods with the Rocq proof assistant is called Software Foundations for a reason. Comparing Formal Methods to foundations is an excellent metaphor that is also useful to get a sense of what it takes to reach adoption. When you have the core language that accurately captures the computational logic of a problem pinned down, when you have the semantics written down, and even your prototype compiler implemented, you have laid out the foundations for what is to come. Strong foundations are important. You can build a tall house on them, they will be robust and durable. But the ideal foundations are the ones you can forget about when you’re busy building the house on top of them.
The lambda-calculus and functional programming are strong foundations for a
programming language. Because they can be relied upon, we can confidently build
on top of them a software engineering tool that will shine on its own merits.
But a real estate agent does not advertise the foundations to sell the house!
They will rather talk about how cozy it feels, or how natural light and breeze
easily pass through it to charm potential buyers. To get it adopted, your DSL
needs to become a product that satisfies the priority expectations of software
engineers for a programming language, which are mostly: a language server
protocol plugin that works so well they never have to leave their
IDE, a build system that offers things like cargo build and
cargo test, being compatible with existing Gitlab and Jira
workflows, a comprehensive documentation and a cool website featuring
a rotating laptop with epic background music.
In a nutshell, adoption for a DSL is all about the top-most layers of the product stack: the build system, IDE plugins and the interactions with software forges. These are the cosy feelings and beautiful natural lighting that will charm software engineers and make them try your DSL.
But if the foundations of a DSL, at the bottom of the stack, are irrelevant for
getting adoption, why care about them at all? Why not just make up some syntax
for a language with a flat, global variable namespace, parse it and printf
some Javascript on-the-fly to eval it inside a Web-based IDE like
Monaco? Why not write a fat, imperative runtime context that contains all
the universe and will bloat anytime you write more than a hundred lines of code?
The curse of shaky programming language foundations
Over the past ten years of my life, I have seen quite a few tech teams using a DSL with shaky foundations as their primary development tool for production code. These DSLs had made it to adoption in one or a couple places, and some of them had quite impressive IDE and build system tooling. But all of them faced an ugly truth: they relied on technological lock-in to stay in production, and prevented their users from having a fulfilling software engineering professional experience. Even with a great top of the stack (IDE plugins, language server, etc.), a DSL with shaky foundations slowly erodes what makes a codebase manageable by a sound team, both technically and socially.
Technically, shaky DSL foundations will create discrepancies and features holes: two language features that cannot be used together, corner cases with wildly incorrect behavior, sub-par specifications of the semantics. Not to mention the growing difficulty to add features to the language, as the compiler accumulates technical debt. Workarounds pile up and create a layered codebase where each snippet has a local and logical reason to exist given the DSL deficiencies, but the global architecture makes no sense.
In such a codebase, intuition no longer reigns, and productivity is achieved through rote learning of a large number of incoherent design patterns in the DSL. Eventually, the evolution of the DSL grinds to a halt while the codebase must carry on. At this point, non-trivial changes in the codebase rely on one or two confident masters that become the bottleneck and liability of the team.
Socially, shaky DSL foundations create a dead end for the professional careers of the software engineers using them. Developers learn new skills when practicing well-thought tools with concepts they can reuse outside of the narrow scope of their current work. Conversely, a DSL user should be able to reuse intuition and concepts from another programming language to speed up their learning curve and correctly structure the codebase. The art of computer programming is about choosing the correct data structure, algorithm, programming paradigm, to solve the right problem. There should always be multiple choices of implementation to choose from, each with its drawbacks and advantages. The DSL should offer some freedom for its users on top of a stable base, so that they can find fulfillment in their daily practice, discuss their choices and preferences with colleagues, and build up skills for their next assignments. I believe this to be how Illich’s notion of conviviality manifests in DSL design. In absence of conviviality for the DSL, members of the teams tend to become external cogs of the codebase, unable to use their experience to enrich their vision of computer science and make progress professionally.
Sadly, most of the damage from shaky DSL foundations shows up late in the process, when technical choices have become irreversible and people’s lives have already been altered. A programming language is a very powerful but closed technical system that restricts a lot the freedom of the user. Solid foundations for DSLs should follow a well-established programming paradigm (imperative programming, object-oriented programming, functional programming, etc.) and limit the number of domain-specific concepts to the bare minimum. There is such a thing as a science of programming languages, that studies how concepts and features can be expressed and implemented in a way that makes a coherent whole, with some room forward for new levels of abstraction that allows the codebase to scale gracefully. Please contact your local Programming Languages/Formal Methods university laboratory or professional experts if you’re looking for advice and guidance as a DSL designer.
To sum it up so far: shiny IDE tooling can get you adoption for your DSL, but it will torment your users eternally and stop scaling fast if you do not give it solid foundations. Luckily, we started with solid foundations for Catala. How much more work did we need to get it adopted?
Turning Catala into an usable product
We needed a lot more work! Catala’s early semantics and design received a lot of help from my PhD advisor Jonathan Protzenko, my former intern Nicolas Chataing, and of course Sarah Lawsky on the topic of default logic. Liane Huttner acted as co-designer of the language, carefully selecting the syntax keywords for maximal compatibility with the minds of lawyers. At the beginning of 2023, we only had a prototype compiler made of ~30k lines of OCaml code. Editing Catala code was done with only basic syntax higlighting, and using the terminal to run the compiler and get back error messages.
From then, the Catala team expanded with one, then two more skilled research engineers working full-time on the project: Louis Gesbert, Romain Primet and Vincent Botbol. They are the main authors of what I present below, with help from Émile Rolley, Estelle Hary and Alain Delaët. I thank them deeply for their work, support and help while proof-reading this blog post.
Expanding the compiler
One line at a time, the compiler was almost completely rewritten and grew 64% more lines of code in three years! Here are the major features that were added to support the industrialization of Catala.
Better architecture. The compiler has a multi-pass architecture, where each pass only performs a small part of the global compilation process. In the prototype, I had written a separate AST for each of the intermediate representations: this kept the code very clear and readable, but did not scale up when adding new features because of code duplication between the various AST versions between the passes. The necessary solution to streamline the evolution of the compiler was to factor most of the AST into a single GADT, which required an extensive refactor of the compiler codebase. We detailed this process in a submission to the ICFP 2023 OCaml workshop.

C and Java backends. The compiler only originally targeted OCaml and Python,
plus Javascript from OCaml thanks to js_of_ocaml. These are nice languages
but they’re not really used by IT departments of large government agencies.
Really, what IT departments of large government agencies need is:
- COBOL for the old stuff;
- Java for the new stuff.
The Java backend took four weeks the develop, from start to finish, based on the
Python backend that already used object-oriented programming. The biggest pain
point was to vendor the dependencies to avoid maven hell for people reusing
artefacts compiled from Catala code. Now, we really didn’t want to learn COBOL
to make a COBOL backend for Catala, especially because there are many flavors of
COBOL to choose from (one per mainframe vendor), making it a legacy rabbit hole
of epic proportions. Fortunately, the Everest project taught us that there
exists a universal language that makes code maximally portable and usable in
large and legacy codebase: ANSI C, also known as C89. COBOL and C89
interoperate quite well together through FFI, so that does the job. We
developped a C89 backend for Catala using closure conversion and other tricks to
de-functionalize our intermediate representations. Currently, the C89 code
generated is standards-compliant but not very idiomatic, as it uses a lot of
pointers and allocations. We’ll improve it in the future, maybe using
KaRaMeL.
Modules and separate compilation. Catala is a DSL but we knew from the start that Catala projects would produce large codebases of 10k+ or even 100k+ lines of code. Codebases this large need to be structured and divided into smaller units that depend on each other while presenting a curated interface. In a nutshell: we needed modules. Modules in Catala are real modules, in the sense that they behave as a separate compilation unit. One call to the compiler handles the compilation of one Catala module. This allows for parallel builds and a real scaling up of the build system (see later). But at the same time, there are situations like debugging where the interpreter really needs to handle the program and dependent modules as a whole. Hence, the Catala compiler supports separate compilation and whole program interpretation at the same time, which was complex to get right.
External modules and outside code. Now that we have modules, we have a
principled and convenient way to give users an escape hatch out of Catala:
externally-implemented modules. These external modules are ideal for calling
Java, C, etc. code within Catala, as long as you can provide a Catala-compatible
interface for the external code. However, external modules come with two
downsides. First, you need to implement them in every target language that you
compile Catala to. This means code duplication (except if you use FFI) and a
bigger Trusted Computing Base (TCB), but unfortunately there’s no way
around that. The second downside is that Catala code using external modules will
not work in the interpreter, severely restricting the usability of the Catala
tooling. Fortunately, we found a solution to address this problem: if you
give an OCaml implementation of the external module, the Catala interpreter
(written in OCaml) can pick it up and run the code as if it had been written
in Catala! This beautiful feature relies on reflection inside the compiler
and the feared Obj module that we managed to tame.
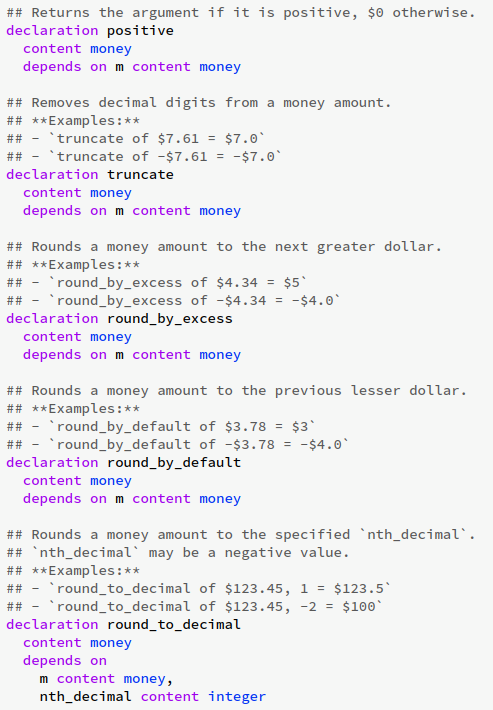
Standard library support. All programming languages need a standard library for any serious use, and Catala is no exception. The compiler needs special treatment for standard library modules, as these are implicitly turned into a dependance of every other module, but not themselves! Furthermore, we do not want to hardcode the list of standard library modules and functions inside the compiler, because we want the minimum amount of friction for people to contribute stuff and expand the standard library. So the compiler treatment of the standard library has to be completely generic, making it harder to implement. Cherry on the cake: a serious standard library should offer functions that perform the same operation on any data type… Polymorphism! Catala has had limited support for polymorphism since the beginning, because of lists. However, polymorphic standard library functions are now user-defined and not hardcoded in the compiler anymore, which means that we had to implement a generic polymorphism treatment in the compiler, again more complex to implement. So far, users can declare and implement functions with polymorphic arguments and return types, but cannot declare polymorphic types themselves. But it is likely that this arms race will lead us to GADT soon…
Returning multiple errors. It is very simple for a compiler to just stop and report an error message at the first error it encounters. Surely it should also be simple to report all the errors in the file before crashing, right? It turns out this is extremely difficult! The ability to show multiple errors and messages is critical for development tooling and developer productivity, but under the hood it often requires radical refactoring of the compiler infrastructure. For instance, reporting several parsing errors requires deep interaction with the parsing loop to insert placeholder token at failure locations and recover the parsing stack in presence of partial inputs. Each compilation stage needs to account for partially successful outcomes and offer a way to continue the analysis without any hope of compiling the program but purely to print more error messages down the way. This work has begun in the Catala compiler, but it requires careful understanding of development patterns to avoid overflowing the user with irrelevant error messages.
The build system cargo cult
Even though Makefiles are an elegant weapon for a more civilized age, as I was
trained by my PhD advisor Jonathan Protzenko, developers of these dangerous and
uncertain times are used to build systems that abstract away dependency
management and compilation steps into a declarative project configuration file.
As a registered member of the reformed church of our lord and savior Rust,
my vision for the Catala build system was simple: replicate whatever cargo
is doing. clerk, our little cargo-like build system, now features 5k lines
of code and uses ninja under the hood.
Project configuration files. Very quickly, features of the build system piled
up and led to a flurry of command line options for clerk which were no longer
manageable by the standard user. Using a project configuration file that
declares where to find the sources, which are the compilation targets, what are
the custom build steps, etc. makes the build configuration much more legible and
user-friendly. Factoring all this information in the configuration file makes
for a really smooth command line user interaction later where commands like
clerk build or clerk test are not cluttered by options and additional
command line arguments. We used TOML as the syntax of our clerk.toml
project file, to copy cargo but also because it’s really convenient for that
use case.
Test, test, test. Writing tests and running them should be very low-friction
for developers, so clerk should make it as easy as possible. We offer two
ways of testing things in Catala: assertion-based testing and cram testing.
Both serve different purposes: assertion-based testing is flexible and precise
for functional and end-to-end tests, while cram testing has a zero setup cost
and tracks regressions perfectly but pollutes the diffs when the code updates.
We let users use both systems at the same time and integrate both in the
clerk test reports that scan the project for tests and run them all in parallel
to see whether something is wrong or not. This requires careful implementation
in the build system and a great attention to details in the report to make
them actionnable for the user (showing the diff betwen results and expected
outcome, reporting code locations for errors, etc.).

Build targets and artifacts. The deliverable output of a Catala build is a set
of source files in a target programming language (C, Java, etc.). The build
system needs to curate those files from all the stuff produced during
compilation, and vendor runtime files to make a standalone artifact with
minimal external dependencies. Because each target language has its own way
to package and organize source files, clerk embarks custom rules for
each target language for seamless integration. Moreover, clerk also needs
to be able to compile and run these source files in each target programming
language, for the sole purpose of running again all the tests of the project
in the generated code to make sure no errors were introduced by the Catala
compiler. This makes for a tricky implementation within clerk that mostly
amounts to cleverly declaring rules and targets for ninja.
Code coverage. Measuring and reporting code coverage for a run of clerk test
is tricky because it requires tight collaboration with the compiler running in
whole program interpretation and aggregating the coverage results for each test
run into a single report for all the tests. clerk uses marshalling to
receive data from the compiler, and serializes the huge coverage map indexed by
code locations into formats legible by IDEs or continuous integration tools.
CLI, meet your new friend IDE
Programming language tooling is not accessed through a command line interface anymore, but rather mostly through an IDE that interacts with the compiler and build system, reporting error messages and more. For a while, the IDE was a pure extension of the programming language tooling, hence specialized IDEs like Eclipse for Java. But the latest trend for emerging languages is to leverage the Language Server Protocol (LSP) to much more easily get an IDE plugin in any IDE that implement the protocol. This is what we did for Catala, leading to the development of two pieces of software that communicate with each other:
- the
catala-lspbinary (written in OCaml) that implements the “server” part of the LSP, callingclerkandcatalaas much as it is needed; - the Catala extension for VSCode (written in Typescript) that implements the “client” part of the LSP to fill out correctly the VSCode interface with the information from the language server.
These two components amount to 8k lines of Typescript and 7k lines of OCaml, with some heavy hurdles that we had to solve.
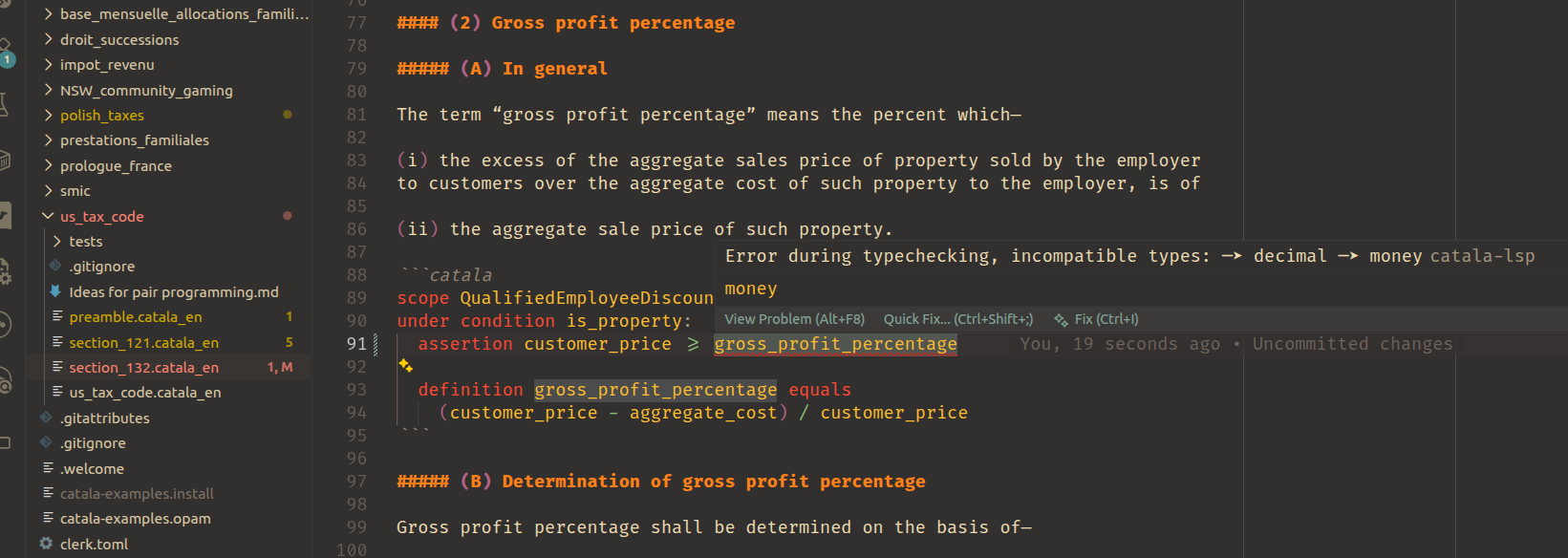
Retrofitting for the LSP. The architecture of the compiler and build system might make it difficult to easily retrieve the information needed for each LSP requests. For instance, the typing in the Catala compiler is done in the default calculus intermediate representation, which is quite deep into the pipeline and far away from the surface language. But inside the IDE plugin, you need to display the type of whatever you’re hovering your mouse over: the LSP server receives a code location and need to return its type. Hence, the LSP server needs to re-shuffle the type information produced by the Catala compiler into a big map from code locations to type information. A lot of LSP requests required a similar retrofitting, for which we had to produce a significant amount of code on top of the compiler and build system.
The state of the project. A central notion for interacting with the IDE is the
project. A project is the set of source code files that will be edited or read
by the developer. In Catala, the scope of the project is defined by the
clerk.toml file that lists directories of source files to be included of the
project, but also the build targets giving the tips of the module dependency
graph. The hard part comes when the user starts editing files. Suppose user is
editing file A.catala_en and has not saved yet. Which version of file
A.catala_en should the LSP server use for typechecking and error messages in
file B.catala_en that uses file A.catala_en? The version stored on disk?
The version currently edited in the IDE? This was a recurring theme during the
development of the IDE, and we had to make difficult choices in edge cases to
guarantee a smooth user experience. Note that Catala’s LSP server is quite
advanced by reacting to the changes in source files rather than a user-triggered
rebuild of the project. Merlin, OCaml’s LSP server, requires a manual
dune build to refresh the interfaces of dependent modules and display the
correct errors messages.
The debugguer. The debugguer looked like a simple addition: normally it should have been sufficient to instrument the Catala interpreter. However, two difficulties arose during implementation. First, the Catala interpreter works with substitution, which is not very handy to record the values of variable during the debugging session. Second, the features of the Debug Adapter Protocol (DAP) used by VSCode make much more sense for a standard, imperative and object-oriented language than for a functional language like Catala. For these two reasons, we had to reimplement a second, environment-based interpreter for the debugguer that duplicates the official interpreter and might introduced subtle bugs. We’ll see if we find a clever way to factorize those two interpreters into a single code base later.
Autoformatting. Tabs or spaces? Taking again inspiration on Rust, we
chose to not let developers lose time on issues of code formatting. But for
that, we needed an autoformatting tool that was both very efficient and very
customizable to embed complex formatting rules that depend on the intricacies of
the Catala syntax. We chose topiary for this job, mostly because it’s
built on top of tree-sitter which we view as the future of compiler
frontends. Hence, there are currently two different parsers for Catala :
- the
menhirparser used by the compiler and all subsequent tooling, including the LSP and VSCode plugin; - the
tree-sitterparser used only bycatala-format, the autoformatter, and syntax highlighting in the Catala book.
While menhir is robust, efficient and very well integrated with the OCaml
ecosystem, we might want to switch to tree-sitter for the IDE tooling because
of its incremental capabilities if IDEs such as VSCode offer more direct
integrated features for tree-sitter-based parsers.
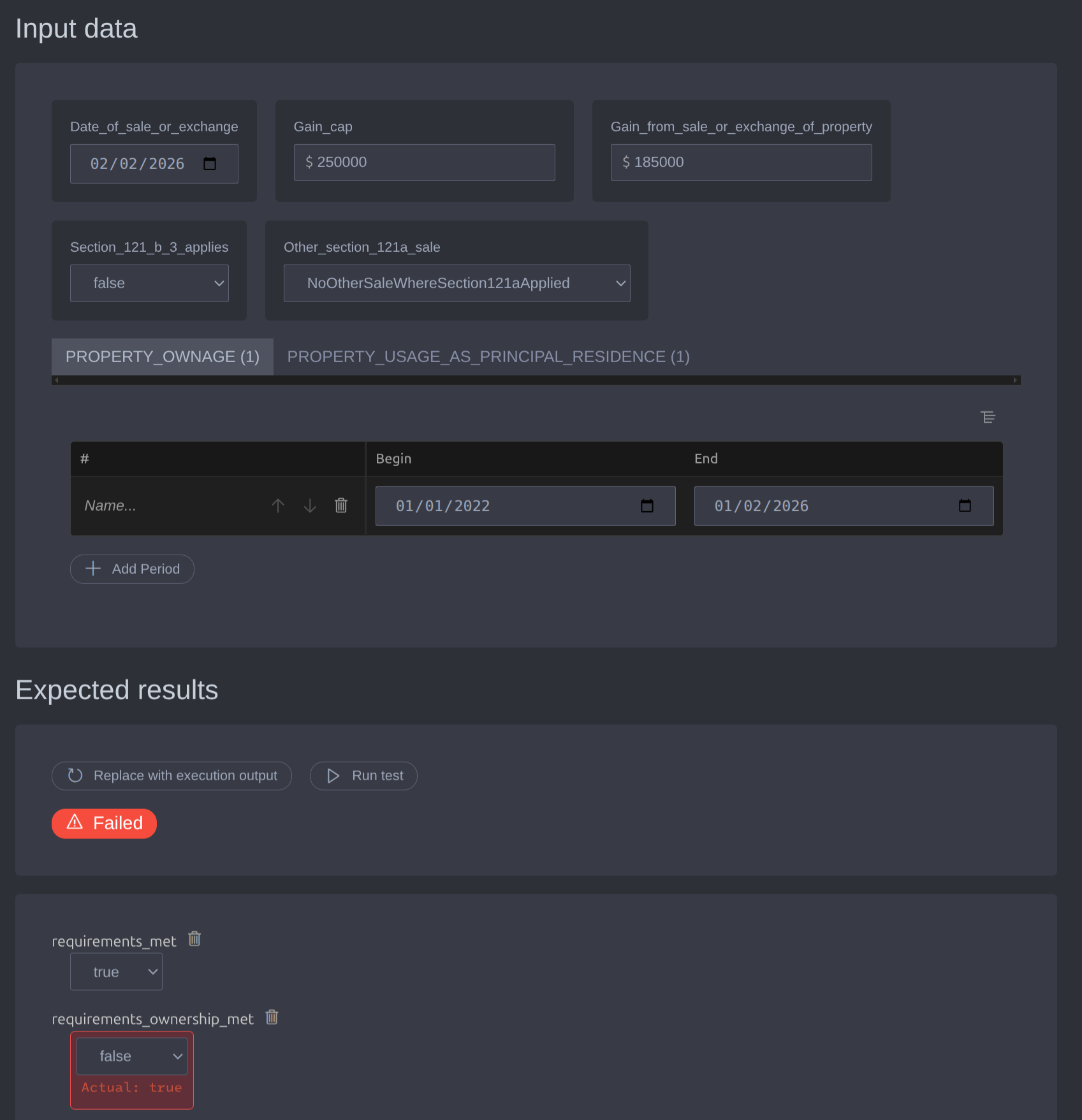
Test edition GUI. Last but not least, we had a very important feature request
by a particular class of users inside a large government agency. They are part
of the development team of a real-world rules engine processing lots of money,
but they do not code per se. Rather, they are in charge of quality assurance
and manage the test base of the rules engine and give the greenlight for future
releases. Before adopting Catala, they were using tooling that let them declare
their test cases in Excel completely independently of the rest of the codebase.
Hence, getting onboard with VSCode, git and the rest of the software
engineering stack was a lot for them, and we wanted to ease the transition as
much as possible. Moreover, there is a real need to generate Web-compatible
forms and GUIs from any scope for end-users in Catala to be able to quickly spin
up simulator and testing tools. Our test editor GUI retrieves the typing
information for each scope from the LSP server, and uses it to generate an
exhaustive HTML/CSS form with intelligent data layout and rich data editing
features. We will continue to test and improve this test editor GUI with our
friends at the government agency, but we’ll also embed it in more and more
places where one needs to build an input to a Catala program without actually
programming it.
Convincing people to use Catala
While all the features above should make it easy and pleasant to use Catala as an everyday tool, we still needed to first convince people to use it. Since Catala is to be used in large and bureaucratic government agencies, the convincing effort needs to be waged on two completely different fronts. On one hand, the developers that will work with Catala everyday. And on the other hand, and the management that needs to sign on the decision legally and financially. These two populations require two completely different sets of arguments to be convinced, and neither can be neglected if you want your tool to be adopted!
Convincing developers: writing a book and answering difficult questions
Catala is a niche DSL whose user base consists of the developers of certain teams in government agencies. We have the luxury to be able to meet in person our users in French government agencies. This personal relation is the key to convincing these developers to switch their current tooling in favor of Catala. Through various meetings, workshops and training sessions, the developers ask the difficult questions related to their pressing needs, and observe first-hand how convenient the solutions offered by Catala are.
Ensuring a quick response to their questions on Zulip is also key to go beyond the in-person sessions, and gradually build trust in the relationship. It is true that your users will always surprise you with ways of manipulating your tool you never thought of! But rather than dismissing these new use cases, taking the time to understand where they come from and what you can offer is valuable. It both helps you, as a tool designer, and the users that might lack the context and experience to choose the appropriate way to code. And if your DSL has solid foundations, it will be a pleasure to realize that you very often have a satisfying answer to give to complex problems that blocked your users with their previous tooling.
Interactions between tool designers and users are cool, but the endgame remains to train your users to be somewhat autonomous and discover the tool at their own pace. For that, you will need documentation! Software documentation needs to both be cohesive (everything at the same place) and varied (different ways to query the documentation). The Diátaxis framework by Daniele Procida really helped us to structure our writing effort by highlighting the need for separated sections of tutorial, guides and references. But it was no small effort : the printed version of the Catala book has more than 250 pages that we had to write by hand. Indeed, apart from the reference part that documents each feature of the language individually and quite mechanically, all the other sections of the book make heavy use of story-telling to take the user by the hand and build a learning curve. The most important part of our documentation is the tutorial, which we rewrote almost completely twice based on user feedback. On the other hand, putting in all this work has worked out and we had several users congratulate us on the quality of the documentation or even better, managed to produce non-trivial Catala code without ever talking to us!
Convincing management: money and risk
Once you have a solid fan base among the developers of an organization, you can try and play a completely different game to convince their management. Far from any flavor of technical detail, what matters at this stage is the economical viability of the project, as well as the legal architecture to structure the financial transfers between users and maintainers.
The easy way is to keep the source code closed, put it inside a company and sell licences or Software as a Service (SaaS). Of course, “easy” is relative here because creating a company and getting the first clients onto the famous product-market fit is no small task. But there are very strong legal, financial and political incentives that favor this way of doing things, starting with the the concept of intellectual property that fundamentally shapes all things digital. Monetizing software through a centralized company that also works on maintenance and evolutions is conceptually simple both for clients that want to pay for a service, and for maintainers that have clear and structured financial incentives to continue doing their work. However, there are cases in which this closed-source economic model is very inefficient at actually boosting the use of a digital tool and provide reliable, affordable service for its users. This is where open-source shines, but open-source is really a collection of non-intellectual-property-based economic models that vary wildly and depend heavily on legal, business and financial skills to work. Releasing the source code is only the first step in the road, and the easiest!
While this blog post will not pretend to become a definitive guide about when to open-source or not a digital project, it is important to tell the story here about how Catala, as an open-source project with a permissive Apache 2 licence, had to match everything in terms of economical and legal structure that is expected from a closed-source, company-based monetization model.
First, the R&D. This is simple: all the research and development for Catala has been funded by Inria, the public French institute for research in Computer Science, by virtue of its mission of public service. Those magic words mean that this funding need not to be amortized by future income: it is a gift by the French people to the world, in the hopes that it will be useful for all. This great gift also comes with great responsibilities, as public money must not be squandered. Among those responsabilities is the documentation of how it was usedi and why, which is one of the objectives of this blog post.
Second, the maintenance and user-specific features. This is where it gets tricky, because the users of Catala are government agencies that are subject to the laws about public procurement. These laws mandate that every time a public institution purchase something, they need to produce a public call to offers that can be answered by different companies, whose offers are then compared on objective criteria defined in advance of the call. Of course, you could ask: why would the government agencies need to buy something with Catala? They can use the tool for free, and maybe they can recruit some maintainers on top of it for extra assurance. While this answer is true, leaders of IT departments in large government agencies need extra assurance for tools that are as critical as Catala for vital functions of the IT system like distributing money.
Hence, IT departments want to buy Service Level Agreements for corrective and preventive maintenance of critical bugs, which has to enter in a public procurement procedure for the public sector. The nice thing with Catala is that there are potentially multiple companies that could offer these services for maintenance and user-specific feature development, since nobody has the exclusivity of the rights to the source code.
But as of now, there is no company that offer those services, because there is no company that has sufficient knowledge and experience on the codebase of Catala. How to solve this conundrum? This question is at the heart of the Apollo program launched by Inria last year, where we aim to transfer innovative technologies from public research to public sector users by involving industrials from the private sector. Catala will be the first project of the program to undergo such a transfer under normal legal rules (an earlier project, TousAntiCovid, benefitted from the exceptional legal regime of the sanitary crisis). Stay tuned for future updates, and if you’re the leader of an IT department in the public sector that want to use Catala, please contact me :)
Third, the long-term roadmap and evolution. In a future world where multiple companies can provide services for Catala and multiple government agencies use it, we will need some coordination and governance to set the roadmap and priorities, as well as determining the allocation of mutualized funds. This can be achieved through some sort of open-source foundation. Inria has a lot of experience about this, which they formalized into InriaSoft consortiums that already exist for a bunch of software coming out of Inria. The legal and economic details of this future consortium will need to be sorted out later based on the exact composition of the committee of users and maintainers.
It is only through the combination of these three layers of legal and economic structures that Catala will mitigate the long-term risks for future users: what if Inria or key contributors leave the project? How will Catala be maintained in 50 years? What if there’s a fork in the community? All things considered, at this extreme level of risk mitigation, open-source stops being a liability and become a strength, because users can always rely on the code independently of the will of a single company. But the intermediate risks concerning the immediate economic viability need to be adressed: money needs to be go from users to maintainers fast to keep the project at flow and make it grow in a sane fashion.
What next?
First of all, thank you for reaching the end of this monstruous blog post. While this was mostly a summary of the hard and silent work that happened in the past five years, I hope to be able to share more positive breaking news about Catala in the near future. In the meantime, continue enjoying niche DSL and crafting languages that people want!